


What is PyCharm?
15th January 2020
HOW ENTERPRISE APPLICATION INTEGRATION BENEFITS BUSINESSES?
17th January 2020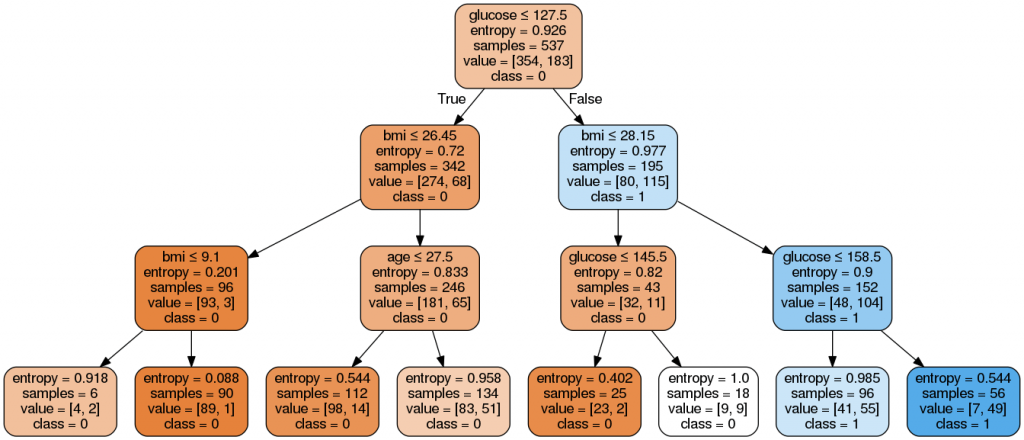
In this decision tree tutorial blog, we will talk about what a decision tree algorithm is, and we will also mention some interesting decision tree examples. The blog will also highlight how to create a decision tree classification model and a decision tree for regression using the decision tree classifier function and the decision tree regressor function, respectively. Also, it will discuss about decision tree analysis, how to visualize a decision tree algorithm in Machine Learning using Python, Scikit-Learn, and the Graphviz tool.
What is Decision Tree? Decision Tree in Python and Scikit-Learn
Decision Tree algorithm is one of the simplest yet powerful Supervised Machine Learning algorithms. Decision Tree algorithm can be used to solve both regression and classification problems in Machine Learning. That is why it is also known as CART or Classification and Regression Trees. As the name suggests, in Decision Tree, we form a tree-like model of decisions and their possible consequences.
Before we dive right into understanding this interesting algorithm, let us take a look at the concepts this blog has to offer.
- Decision Tree Algorithm Example
- Types of Decision Tree Algorithms
- Terminologies related to Decision Tree Algorithms
- Advantages of Decision Tree Algorithms
- Disadvantage of Decision Tree Algorithms
- How Does a Decision Tree in Machine Learning Work?
- Decision Tree in Machine Learning: Decision Tree Classifier and Decision Tree Regressor
- Creating and Visualizing a Decision Tree Regression Model in Machine Learning Using Python
Without much delay, let’s get started!
Decision Tree Algorithm Example
Monica’s cousin Marry is visiting Central Park this weekend. Now, Monica needs to make some plans for the weekend, whether to go out for shopping, go for a movie, spend time in the Central Park coffee shop, or just stay in and play a board game. Well, she decides to create a Decision Tree to make things easy.
Here, the interior nodes represent different tests on an attribute (for example, whether to go out or stay in), branches hold the outcomes of those tests, and leaf nodes represent a class label or some decision taken after measuring all attributes. Each path from the root node to the leaf nodes represents a decision tree classification rule.
Rule 1: If it’s not raining and not too sunny, then go out for shopping.
Rule 2: If it’s not raining but too sunny outside, then go for a movie.
Rule 3: If it’s raining outside and the cable has signal, then watch a TV show.
Rule 4: If it’s raining and the cable signal fails, then spend time in the coffee shop downstairs
That’s how a decision tree helps Monica to make the perfect weekend plan with her cousin.
Types of Decision Tree Algorithms
There are two types of decision trees. They are categorized based on the type of the target variable they have. If the decision tree has a categorical target variable, then it is called a ‘categorical variable decision tree’. Similarly, if it has a continuous target variable, it is called a ‘continuous variable decision tree’.
Terminologies Related to Decision Tree Algorithms
- Root Node: This node gets divided into different homogeneous nodes. It represents entire sample.
- Splitting: It is the process of splitting or dividing a node into two or more sub-nodes.
- Interior Nodes: They represent different tests on an attribute.
- Branches: They hold the outcomes of those tests.
- Leaf Nodes: When the nodes can’t be split further, they are called leaf nodes.
- Parent and Child Nodes: The node from where sub-nodes are created is called a parent node. And, the sub-nodes are called the child nodes.
Advantages of Decision Tree Algorithms
- Easy to understand
- Requires minimum data cleaning
- No constraint on the data type
Disadvantage of Decision Tree Algorithms
- Possibility of over fitting
How Does a Decision Tree in Machine Learning Work?
The process of training and predicting the target features using a decision tree in Machine Learning is given below:
- Feed a dataset, containing a number of training instances, with a set of features and a target
- Train the decision tree classification or regression models with the help of DecisionTreeClassifier () or DecisionTreeRegressor () methods, and add the required criterion while building the decision tree model
- Use Graphviz to visualize the decision tree model
That’s it! Your decision tree model is ready.
Decision Tree in Machine Learning – DecisionTreeClassifier () and DecisionTreeRegressor ()
DecisionTreeClassifier (): It is nothing but the decision tree classifier function to build a decision tree model in Machine Learning using Python. The DecisionTreeClassifier() function looks like this:
DecisionTreeClassifier (criterion = ‘gini’, random_state = None, max_depth = None, min_samples_leaf =1)
Here are a few important parameters:
- criterion: It is used to measure the quality of a split in the decision tree classification. By default, it is ‘gini’; it also supports ‘entropy’.
- max_depth: This is used to add maximum depth to the decision tree after the tree is expanded.
- min_samples_leaf: This parameter is used to add the minimum number of samples required to be present at a leaf node.
DecisionTreeRegressio (): It is the decision tree regressor function used to build a decision tree model in Machine Learning using Python. The DecisionTreeRegressor () function looks like this:
DecisionTreeRegressor (criterion = ‘mse’, random_state =None , max_depth=None, min_samples_leaf=1,)
- criterion: This function is used to measure the quality of a split in the decision tree regression. By default, it is ‘mse’ (the mean squared error), and it also supports ‘mae’ (the mean absolute error).
- max_depth: This is used to add maximum depth to the decision tree after the tree is expanded.
- min_samples_leaf: This function is used to add the minimum number of samples required to be present at a leaf node.
Creating and Visualizing a Decision Tree Regression Model in Machine Learning Using Python
Problem Statement: Use Machine Learning to predict the selling prices of houses based on some economic factors. Build a model using decision tree in Python.
Dataset: Boston Housing Dataset
Model Building
Let us build the regression model of decision tree in Python.
Step 1: Load required packages
Step 2: Load the Boston dataset
Step 3: Visualize the dataset using a scatter plot
Step 4: Define the features and the target
Step 5: Split the dataset into train and test sets
Here, ‘test_size = 0.2’ means that the test set will be 20 percent of the whole dataset and the training set’s size will be 80 percent of the entire dataset.
Step 6: Build the model with the decision tree regressor function
Step 7: Visualize the tree using Graphviz
Step 8: Compare y_test and y_pred
Step 9: Finding the RMSE value



{kind=link}