


Risk Management in Testing
5th February 2020
Next Level Visuals with Adobe Photoshop
10th February 2020
Why do we need to do database partitioning? Or, what are the benefits of database partitioning? In this blog, you will get all your answers. But, before that you should know what partitioning is. In simple words, partitioning means dividing into parts or subdividing. With the help of partitioning techniques, you can manage large database tables.
How about having some more knowledge on the massive databases? Yes, this article is a source of information for you to update your awareness on databases in this Big Data age.

Today, in this big data planet, modern organizations run with crucial conditions relating to data administration and problems of sheltered data storage. Companies deal with huge terabytes of information, and the arrangement of their over-sized databases has become one of the vital concerns for the tech community today. In order to come up with brilliant ways of upholding such big data, proper techniques have to be pursued.
Introduction to Partitioning
A big problem can be solved easily when it is chopped into several smaller sub-problems. That is what the partitioning technique does. It divides a big database containing data metrics and indexes into smaller and handy slices of data called as partitions. The partitioned tables are directly used by SQL queries without any alteration. Once the database is partitioned, the data definition language can easily work on the smaller partitioned slices, instead of handling the giant database altogether. This is how partitioning cuts down the problems in managing large database tables.
The partitioning key consists of a single or supplementary columns with the intention of determining the partition wherever the rows will be stored. Spark modifies the partitions by using these partition keys.
Partitioning Key Extensions
Key extensions assist in signifying the keys used for partitioning processes. These extensions are explained below.
- Reference Partitioning: Reference partitioning facilitates the division of two databases associated with one another by referential limitations. By activating the primary and the foreign keys, it produces a new partition key from another active relationship.
- Virtual Column-based Partitioning: The partition of a database is possible even when the partition keys are physically unavailable. This is possible by the virtual column-based partitioning method which creates logical partition keys using the columns of the data table.
Partitioning Techniques
Spark provides three information allocation processes, and they are:
- Hash
- Range
- List
Using these information allocation processes, database tables are partitioned in two methods: single-level partitioning and composite partitioning.
- Single-level Partitioning: Any data table is addressed by identifying one of the above data distribution methodologies, using one or more columns as the partitioning key. The techniques are:
- Hash Partitioning
- Range Partitioning
- List Partitioning
- Hash Partitioning
Oracle has got a hash algorithm for recognizing partition tables. This algorithm uniformly divides the rows into various partitions in order to make all partitions of identical dimensions. The process carried out using this hash algorithm to divide database tables into smaller divisions is termed as the hash partitioning.
Hash partitioning is the perfect means for sharing data consistently among different devices. This partitioning method is a user-friendly partitioning system, particularly when the information to be detached has no apparent partitioning key.
- Range Partitioning
Range partitioning divides the information into a number of partitions depending on the ranges of values of the particular partitioning keys for every partition of data. It is a popular partitioning scheme which is normally used with dates. For example, for representing the days of the month of May, it will have a table with the column name as ‘May’ and rows with dates from May 1 to May 31.
All partitions smaller than a particular partition come before the VALUES LESS THAN clause, while all partitions higher than the particular partition come after the VALUES LESS THAN clause of that partition. For representing the highest range partition, the MAXVALUE clause is used.
- List Partitioning
List partitioning allows to openly organize the rows, which are divided into partitions by spelling out a roll of distinct standards for the partitioning key in an account for every division. Using this scheme of partitioning, even dissimilar and shuffled information tables can be managed in a comfortable approach.
In order to avoid errors during the partition of rows in the giant database, the addition of the probable terms into the table formed by the list partitioning method can be avoided by using the default partition process.
2. Composite Partitioning: The composite partitioning method includes a minimum of two partitioning procedures on the data. Initially, the database table will be divided by using one partition procedure, and then the output partition slices are again partitioned further by using another partitioning procedure.
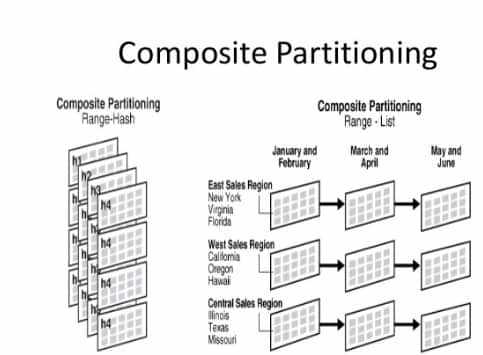
Types of Composite Partitioning
- Composite Range–Range Partitioning
- Composite Range–Hash Partitioning
- Composite Range–List Partitioning
- Composite List–Range Partitioning
- Composite List–Hash Partitioning
- Composite List–List Partitioning
- Composite Range–Range Partitioning
In this composite partitioning, the partition and the subpartition are done by the same range partitioning system. Since in this partition you usually use dates, the process may be done by partitioning using the launch_date followed by sub-partitioning which is followed by the purchasing_date.
- Composite Range–Hash Partitioning
This is a mixture of the range and the hash partitioning methods. The data table is first divided using the range partitioning method the results of which are again subdivided into subdivisions using the hash partitioning scheme. It combines the benefits of the two methods, i.e., the controlling power of the range method and the placing of information and striping offered by the hash method.
- Composite Range–List Partitioning
Composite range–list partitioning chops information by means of the range method, and every division further divides by means of the list technique.
- Composite List–Range Partitioning
In this composite division, the data is first partitioned using the list partitioning scheme. Once the data is arranged into various partitions in the list, all these listed partitions are subdivided using the range partition mode.
- Composite List–Hash Partitioning
This allows hash sub-partitioning on a list of already list-partitioned data. Here, the list partition is followed by the hash partition process.
- Composite List–List Partitioning
This type of composite partitioning scheme includes both partitioning and sub-partitioning done with the help of the List partitioning scheme. The initial giant table is divided by the list method, and the results derived by it are again chopped down into subpartitions using the same list method, providing even smaller slices of data.
Benefits of Partitioning
- It advances query functionalities. Because, queries can be easily and rapidly solved for a collection of partitions instead of solving them for a giant database. Hence, the functionality and performance level gain improvement.
- The planned intermission time gets abridged.
- It facilitates information administration procedures like information loading, index formation and restoration, and backup and upturn at the partition stage. As a result, processes become faster.
- Parallel implementation offers detailed benefits to optimize resource utilization and lessens the implementation time too. Parallel execution next to partitioned substances is a solution for scalability in a crowded setting.
Partitioning techniques not only improves the running and management of very large data centers, but it even allows the medium-range and smaller databases to take pleasure of its benefits. Although it can be implemented to all sizes of databases, it is most important for the databases that handle big data. The scalability of the partitioning techniques proves that the advantages the smaller data centers are facilitated with do not get changed when it comes to the bigger data centers.


{kind=link}
{kind=link}
{kind=link}