


What is Microsoft Azure?
26th December 2019
What is Artificial Neural Network?
1st January 2020
Apache Hbase is a popular and highly efficient Column-oriented NoSQL database built on top of Hadoop Distributed File System that allows performing read/write operations on large datasets in real time using Key/Value data.
Introduction to Apache Hbase
Apache HBase is an Apache Hadoop project and Open Source, non-relational distributed Hadoop database that had its genesis in the Google’s Bigtable. The programming language of HBase is Java. Today it is an integral part of the Apache Software Foundation and the Hadoop ecosystem. It is a high availability database that exclusively runs on top of the HDFS and provides the Capabilities of Google Bigtable for the Hadoop framework for storing huge volumes of unstructured data at breakneck speeds in order to derive valuable insights from it.
It has an extremely fault-tolerant way of storing data and is extremely good for storing sparse data. Sparse data is something like looking for a needle in a haystack. A real-life example of sparse data would be like looking for someone who has spent over $100,000 dollars in a single transaction on Amazon among the tens of millions of transactions that happen on any given week.
| Criteria | HBase |
| Cluster basis | Hadoop |
| Deployed for | Batch Jobs |
| API | Thrift or REST |
The Architecture of Apache HBase
The Apache HBase carries all the features of the original Google Bigtable paper like the Bloom filters, in-memory operations and compression. The tables of this database can serve as the input for MapReduce jobs on the Hadoop ecosystem and it can also serve as output after the data is processed by MapReduce. The data can be accessed via the Java API or through the REST API or even the Thrift and AVRO gateways.
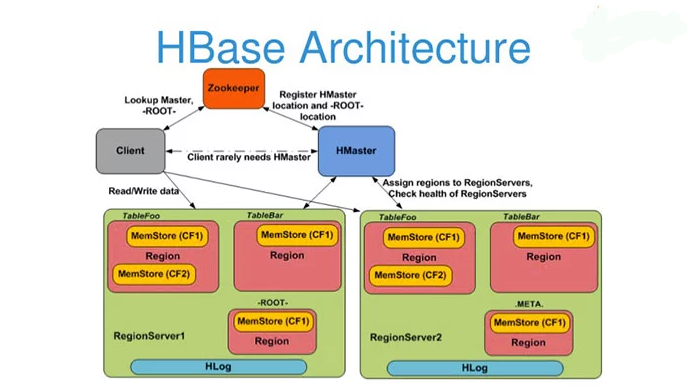
What HBase is that it is basically a column-oriented key-value data store, and the since it works extremely fine with the kind of data that Hadoop process it is natural fit for deploying as a top layer on HDFS. It is extremely fast when it comes to both read and write operations and does not lose this extremely important quality even when the datasets are humongous. Therefore it is being widely used by corporations for its high throughput and low input/output latency. It cannot work as a replacement for the SQL database but it is perfectly possible to have an SQL layer on top of HBase to integrate it with the various business intelligence and analytics tools.
Why should you use the HBase technology?
HBase is one of the core components of the Hadoop ecosystem along with the other two being HDFS and MapReduce. As part of the Hortonworks Data Platform the Apache Hadoop ecosystem is available as a highly secure, enterprise ready big data framework. It is being regularly deployed by some of the biggest companies like Facebook messaging system and so on. Some of the salient features of HBase that makes it one of the most sought after message storing system is as follows:
- It has a completely distributed architecture and can work on extremely large scale data
- It works for extremely random read and write operations
- It has high security and easy management of data
- It provides an unprecedented high write throughput
- Scaling to meet additional requirements is seamless and quick
- Can be used for both structured and semi-structured data types
- It is good when you don’t need full RDBMS capabilities
- It has a perfectly modular and linear scalability feature
- The data reads and writes are strictly consistent
- The table sharding can be easily configured and automatized
- The various servers are provided automatic failover support
- The MapReduce jobs can be backed with HBase Tables
- Client access is seamless with Java APIs.