


Git vs. GitHub: What’s the Difference?
26th June 2020
5 mistakes to avoid on your Shopify website
30th June 2020
Among the wide variety of storage solutions that are provided by Amazon, Amazon Glacier is the one that is designed to be the most economical cloud storage solution. And of course, coming from Amazon Web services, this storage service is also well known for the data security that it offers. Any kind of data can be stored in AWS Glacier, regardless of the format of the data, be it a video file, an image file, a single text file, or zip files. In this tutorial, we will dive deeper into the concepts of Amazon Glacier and understand all the fundamentals of this cloud storage solution.
What is Amazon Glacier?
Amazon Glacier is an economical and online storage solution by AWS and like S3 it provides simple, secure, cloud-based data storage that can be easily scaled up and down as needed. But unlike S3, which is designed for frequently accessed data and is mainly intended to provide quick access to data, AWS Glacier is designed for long term storage for cold data that will not be needed to retrieve very frequently and quickly.
So, to define Amazon Glacier again, AWS Glacier is a long term and low-cost cloud storage solution, optimized for infrequently used data or otherwise known as “cold data”.
Following are some interesting facts about Amazon Glacier:
- An unlimited amount of data can be stored in Amazon Glacier.
- Amazon Glacier provides average annual durability of 99.999999999%
- While the data is uploaded in Amazon Glacier, it stores the data across multiple availability zones before it confirms the successful upload.
- One can enjoy the Amazon Glacier storage solution at the cost of just $0.007 per GB per month.
- Data stored in Amazon Glacier is immutable and is encrypted at rest by default.
Archives and Vaults in AWS Glacier
Archives and Vaults are at the core of the Glacier data model. Glacier is a REST-based web service, which means that it relies on the REST architecture. Job and Notification-configuration resources are included in the Glacier data model.
Before starting with AWS Glacier, we need to know why Glacier needs archives and vaults. Glacier uses Archives and Vaults to store data.
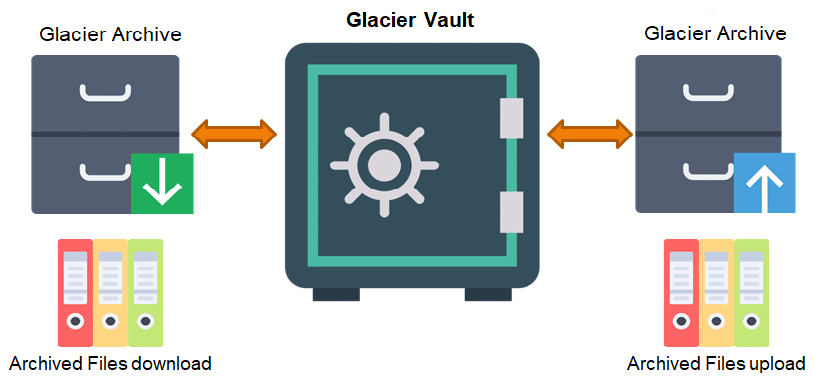
Archives
The actual data is stored in archives. You can store any type of data in an archive, such as images, video, audio and documents. There are two ways to upload files to an archive. You can directly upload a single file and create an archive or you can “TAR” or “ZIP” multiple files and upload it as a single archive.
Following are some important pointers about Archives:
- Maximum size of a single archive is 40 terabytes
- Unlimited number of archives can be created
- Virtually unlimited data can be stored in S3 Glacier
- An archive cannot be updated after creation
Vaults
We have stored the data in the archives, but where will the archives be stored and grouped? That is where Vaults come into play. Vaults are containers where you can store multiple archives.
Following are some important pointers about Vaults:
- 1000 vaults are allowed for a single AWS account.
- You can set every vault with access policies to make it available or deny for users
- You can use AWS SDKs to do a variety of vault operations
- create vault
- delete vault
- lock vault
- list vault metadata
- tag vaults
Features in Amazon Glacier
we will be looking at the key features of Amazon S3 Glacier.
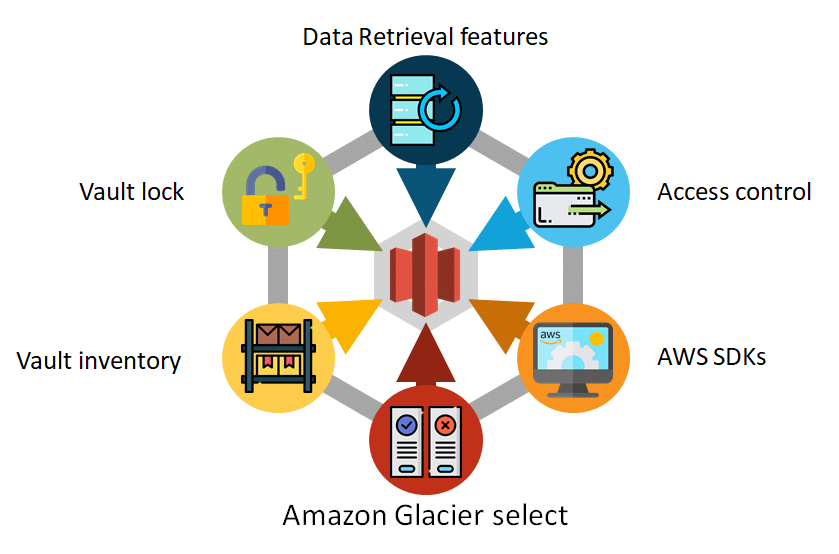
The key features of Glacier are:
- Data Retrieval features
- Amazon Glacier select
- Vault lock
- Access control
- Vault inventory
- AWS Software Development Kits (SDKs)
Data Retrieval features
- These are features provided by Amazon Glacier for different speeds and making it more cost-effective. There are three different retrieval methods – Expedited, Standard, and Bulk. We will look at these methods in depth in the next part of this blog.
Amazon Glacier Select
- AWS Let’s you to run queries directly on the archives rather than extracting the entire archive which reduces the access time.
Vault lock
- Glacier lets you create locks on individual vaults by applying policies. For instance, WORM (Write Once Read Many) policies can be used to prevent further edits after uploading.
Access control
- AWS IAM can be used to securely access the management console and also secure the S3 Glacier data.
- You can create multiple users using IAM and specify separate user policies for every individual to restrict or allow access to certain parts
Vault Inventory
- Amazon S3 Glacier always has an inventory of all the archives in every vault. The inventory will contain the name, creation date, and description of the archives.
AWS SDKs
- All upload and retrieval functions are done by AWS SDKs or APIs (Application Programming Interfaces). AWS SDK is supported by multiple programming languages and frameworks like JAVA, .NET, Python, and PHP. Programming is made easy by SDKs and APIs.
Data retrieval and retrieval policies in Glacier
As we know, Data retrieval is a key feature in Glacier. Now, let us look at it in detail. There are three types of Data Retrieval:
- Expedited
- These type of retrievals can happen within 1 – 5 minutes. This is used under an urgent circumstances when you need to access data quickly from a subset of archives.
- Standard
- This retrieval takes 3 – 5 hours to make the data accessible. This is the most commonly used retrieval method.
- Bulk
- Bulk retrieval is used to access significant portions of data with cost-effectiveness.
Benefits of AWS Glacier
- Fast Retrievals (1 – 5 minutes)
- AWS Glacier provides lightning-fast data retrieval. You can retrieve data within 1 – 5 mins if it is Expedited. Also, Standard is available which takes 3 – 5 hours.
- Scalability & Durability
- Glacier has a 99.999999999% durability. Uploaded data is automatically distributed across a minimum of three physical Availability Zones that are geographically separated.
- Low Cost
- Glacier allows you to store large amounts of data at a very low cost and also provide fast retrieval speeds. It would only cost you 0.0007$ per month for storing per GB and this is applicable only when it exceeds the free tier limit. You can receive 10 GB of data every month.
- Highly supported by Partners, Vendors, and other AWS services
- Not only AWS services support Glacier. Third-party software and MNC vendors who need to do Backup & Recovery, Archiving and Disaster Recovery use Amazon S3 Glacier.
- Easy Querying
- Amazon S3 Glacier is the only archiving service that allows a user to query in the management console itself and retrieve separate datasets from a huge data archive.
When can Amazon Glacier be used?
all the scenarios where you can use Amazon S3 Glacier.
- Applications that have a lot of multimedia data coming in can use Amazon Glacier because of the amount of data can sometimes reach petabytes too. For example, Twitter needs Glacier.
- Research and Development organizations use huge data sets for their scientific analysis. They need a way to store all the input, training, and output data.
- To replace legacy storage systems. Firms who want to shift from traditional data storage to cloud storage can use Amazon Glacier. The main reason is there is no upfront cost and also there is no burden of maintaining the hardware.
- Hospitals need to store patient information for decades to meet regulatory requirements. Huge hospital networks need Glacier because the data can often cross petabytes.


{kind=link}
{kind=link}