
How to Choose a Technology Stack Meeting All the Project’s Peculiarities
23rd October 2019
What Is Ransomware?
2nd November 2019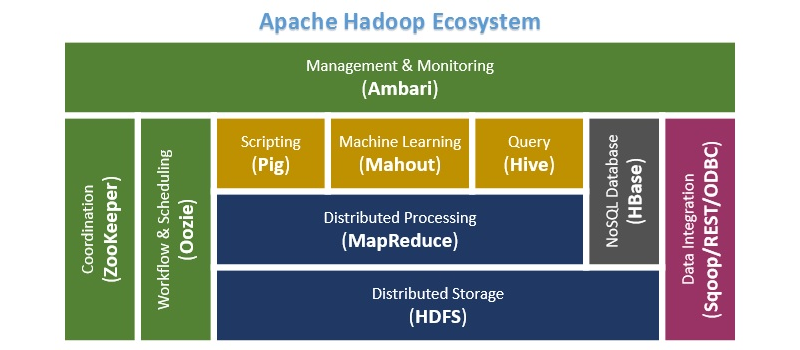
Apache Hadoop is a collection of open-source software utilities that facilitate using a network of many computers to solve problems involving massive amounts of data and computation. It provides a software framework for distributed storage and processing of big data using the MapReduce programming model. Originally designed for computer clusters built from commodity hardware—still the common use—it has also found use on clusters of higher-end hardware. All the modules in Hadoop are designed with a fundamental assumption that hardware failures are common occurrences and should be automatically handled by the framework.
The core of Apache Hadoop consists of a storage part, known as Hadoop Distributed File System (HDFS), and a processing part which is a MapReduce programming model. Hadoop splits files into large blocks and distributes them across nodes in a cluster. It then transfers packaged code into nodes to process the data in parallel. This approach takes advantage of data locality,where nodes manipulate the data they have access to. This allows the dataset to be processed faster and more efficiently than it would be in a more conventional supercomputer architecture that relies on a parallel file system where computation and data are distributed via high-speed networking.
The base Apache Hadoop framework is composed of the following modules:
- Hadoop Common – contains libraries and utilities needed by other Hadoop modules;
- Hadoop Distributed File System (HDFS) – a distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster;
- Hadoop YARN – (introduced in 2012) a platform responsible for managing computing resources in clusters and using them for scheduling users’ applications;
- Hadoop MapReduce – an implementation of the MapReduce programming model for large-scale data processing.
The term Hadoop is often used for both base modules and sub-modules and also the ecosystem, or collection of additional software packages that can be installed on top of or alongside Hadoop, such as Apache Pig, Apache Hive, Apache HBase, Apache Phoenix, Apache Spark, Apache ZooKeeper, Cloudera Impala, Apache Flume, Apache Sqoop, Apache Oozie, and Apache Storm.
Apache Hadoop’s MapReduce and HDFS components were inspired by Google papers on MapReduce and Google File System.
The Hadoop framework itself is mostly written in the Java programming language, with some native code in C and command line utilities written as shell scripts. Though MapReduce Java code is common, any programming language can be used with Hadoop Streaming to implement the map and reduce parts of the user’s program. Other projects in the Hadoop ecosystem expose richer user interfaces.
Hadoop and big data
Hadoop runs on commodity servers and can scale up to support thousands of hardware nodes. The Hadoop Distributed File System (HDFS) is designed to provide rapid data access across the nodes in a cluster, plus fault-tolerant capabilities so applications can continue to run if individual nodes fail. Those features helped Hadoop become a foundational data management platform for big data analytics uses after it emerged in the mid-2000s.
Because Hadoop can process and store such a wide assortment of data, it enables organizations to set up data lakes as expansive reservoirs for incoming streams of information. In a Hadoop data lake, raw data is often stored as is so data scientists and other analysts can access the full data sets, if need be; the data is then filtered and prepared by analytics or IT teams, as needed, to support different applications.
Data lakes generally serve different purposes than traditional data warehouses that hold cleansed sets of transaction data. But, in some cases, companies view their Hadoop data lakes as modern-day data warehouses. Either way, the growing role of big data analytics in business decision-making has made effective data governance and data security processes a priority in data lake deployments and Hadoop systems in general.
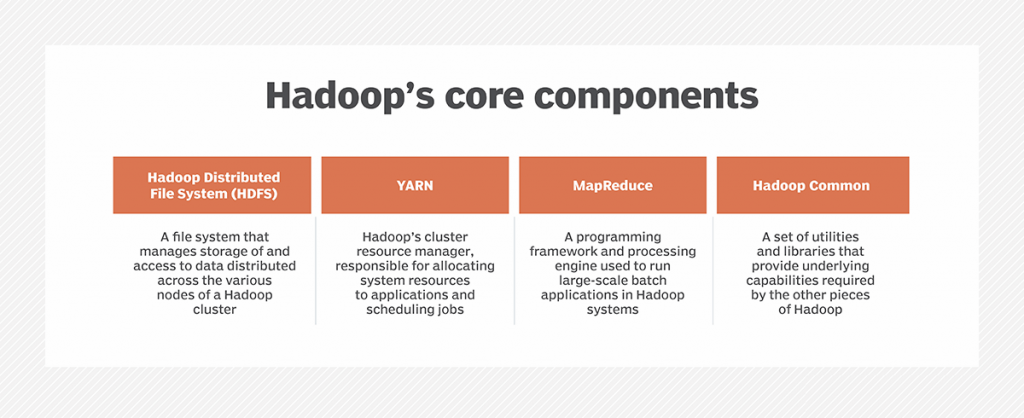
Components of Hadoop and how it works
The core components in the first iteration of Hadoop were MapReduce, HDFS and Hadoop Common, a set of shared utilities and libraries. As its name indicates, MapReduce uses map and reduce functions to split processing jobs into multiple tasks that run at the cluster nodes where data is stored and then to combine what the tasks produce into a coherent set of results. MapReduce initially functioned as both Hadoop’s processing engine and cluster resource manager, which tied HDFS directly to it and limited users to running MapReduce batch applications.
That changed in Hadoop 2.0, which became generally available in October 2013 when version 2.2.0 was released. It introduced Apache Hadoop YARN, a new cluster resource management and job scheduling technology that took over those functions from MapReduce. YARN — short for Yet Another Resource Negotiator, but typically referred to by the acronym alone — ended the strict reliance on MapReduce and opened up Hadoop to other processing engines and various applications besides batch jobs. For example, Hadoop can now run applications on the Apache Spark, Apache Flink, Apache Kafka and Apache Storm engines.
In Hadoop clusters, YARN sits between HDFS and the processing engines deployed by users. The resource manager uses a combination of containers, application coordinators and node-level monitoring agents to dynamically allocate cluster resources to applications and oversee the execution of processing jobs in a decentralized process. YARN supports multiple job scheduling approaches, including a first-in-first-out queue and several methods that schedule jobs based on assigned cluster resources.
The Hadoop 2.0 series of releases also added high availability and federation features for HDFS, support for running Hadoop clusters on Microsoft Windows servers and other capabilities designed to expand the distributed processing framework’s versatility for big data management and analytics.
Hadoop 3.0.0 was the next major version of Hadoop. Released by Apache in December 2017, it added a YARN Federation feature designed to enable YARN to support tens of thousands of nodes or more in a single cluster, up from a previous 10,000-node limit. The new version also included support for GPUs and erasure coding, an alternative to data replication that requires significantly less storage space.
Subsequent 3.1.x and 3.2.x updates enabled Hadoop users to run YARN containers inside Docker ones and introduced a YARN service framework that functions as a container orchestration platform. Two new Hadoop components were also added with those releases: a machine learning engine called Hadoop Submarine and the Hadoop Ozone object store, which is built on the Hadoop Distributed Data Store block storage layer and designed for use in on-premises systems.
Hadoop’s importance to users
Despite the emergence of alternative options, especially in the cloud, Hadoop is still an important and valuable technology for big data users for the following reasons:
- It can store and process vast amounts of structured, semistructured and unstructured data, quickly.
- It protects application and data processing against hardware failures. If one node in a cluster goes down, processing jobs are automatically redirected to other nodes to ensure applications continue to run.
- It doesn’t require that data be preprocessed before being stored. Organizations can store raw data in HDFS and decide later how to process and filter it for specific analytics uses.
- It’s scalable, so companies can easily add more nodes to enable their systems to handle more data.
- It can support real-time analytics to help drive better operational decision-making, as well as batch workloads for historical analysis.
Hadoop applications and use cases
YARN greatly expanded the applications that Hadoop clusters can handle to include interactive querying, stream processing and real-time analytics. For example, manufacturers, utilities, oil and gas companies, and other businesses are using real-time data that’s streaming into Hadoop systems from IoT devices in predictive maintenance applications to try to detect equipment failures before they occur. Fraud detection, website personalization and customer experience scoring are other real-time use cases.
Some other common use cases for Hadoop include the following:
- Customer analytics. Examples include efforts to predict customer churn, analyze clickstream data to better target online ads to web users, and track customer sentiment based on comments about a company on social networks.
- Risk management. Financial services companies use Hadoop clusters to develop more accurate risk analysis models for use internally and by their customers. They also build investment models and develop trading algorithms in Hadoop-based big data systems.
- Operational intelligence. For example, Hadoop can help telecommunications companies better understand switching performance and network and frequency utilization for capacity planning and management. By analyzing how mobile services are consumed and the available bandwidth in geographic regions, telcos can also determine the best places to locate new cell towers and respond more quickly to network problems.
- Supply chain management. Manufacturers, retailers and trucking companies use Hadoop systems to track the movement of goods and vehicles so they can determine the costs of various transportation options. In addition, they can analyze large amounts of historical, time-stamped location data to map out potential delays and optimize delivery routes.
The technology has been deployed for many other uses, as well. For example, insurers use Hadoop for applications such as analyzing policy pricing and managing safe driver discount programs. Also, healthcare organizations look for ways to improve treatments and patient outcomes with Hadoop’s aid.
Big data tools associated with Hadoop
The ecosystem that has been built up around Hadoop includes a range of other open source technologies that can complement and extend its basic capabilities. The list of related big data tools includes these examples:
- Apache Flume, a tool used to collect, aggregate and move large amounts of streaming data into HDFS;
- Apache HBase, a distributed database that’s often paired with Hadoop;
- Apache Hive,a SQL-on-Hadoop tool that provides data summarization, query and analysis;
- Apache Oozie, a server-based workflow scheduling system to manage Hadoop jobs;
- Apache Phoenix, a SQL-based massively parallel processing database engine that uses HBase as its data store;
- Apache Pig, a high-level platform for creating programs that run on Hadoop clusters;
- Apache Sqoop, a tool to help transfer bulk data between Hadoop and structured data stores, such as relational databases; and
- Apache ZooKeeper, a configuration, synchronization and naming registry service for large distributed systems.
History of Hadoop
Hadoop was created by computer scientists Doug Cutting and Mike Cafarella, initially to support processing in the Nutch open source search engine and web crawler. After Google published technical papers detailing its Google File System and MapReduce programming framework in 2003 and 2004, Cutting and Cafarella modified earlier technology plans and developed a Java-based MapReduce implementation and a file system modeled on Google’s.
In early 2006, those elements were split off from Nutch and became a separate Apache subproject, which Cutting named Hadoop after his son’s stuffed elephant. At the same time, Cutting was hired by internet services company Yahoo, which became the first production user of Hadoop later in 2006.
Use of the framework grew over the next few years, and three independent Hadoop vendors were founded: Cloudera in 2008, MapR Technologies a year later and Hortonworks as a Yahoo spinoff in 2011. In addition, AWS launched a Hadoop cloud service called Elastic MapReduce in 2009. That was all before Apache released Hadoop 1.0.0, which became available in December 2011 after a succession of 0.x releases.

Evolution of the Hadoop market
In addition to AWS, Cloudera, Hortonworks and MapR, several other IT vendors — most notably, IBM, Intel and Pivotal Software — entered the Hadoop distribution market. However, the latter three companies all later dropped out after failing to make much headway with Hadoop users. Intel stopped offering its distribution and invested in Cloudera in 2014, while Pivotal and IBM exited the market and agreed to resell the Hortonworks version of Hadoop in 2016 and 2017, respectively.
Even the remaining vendors hedged their bets on Hadoop itself by expanding their big data platforms to also include Spark and numerous other technologies. Spark, which runs both batch and real-time workloads, has ousted MapReduce in many batch applications and can bypass HDFS to access data from Amazon Simple Storage Service and other cloud object storage repositories. In 2017, both Cloudera and Hortonworks dropped the word Hadoop from the names of their rival conferences for big data users.
The market consolidation continued in 2019, when Cloudera acquired Hortonworks in a merger of the two former rivals and Hewlett Packard Enterprise bought the assets of MapR after the big data vendor warned that it might have to shut down if it couldn’t find a buyer or new funding.
Increasingly, the focus of Hadoop users and vendors alike is on cloud deployments of big data systems. In addition to Amazon EMR, as Elastic MapReduce is now called, organizations looking to use Hadoop in the cloud can turn to a variety of managed services, including Microsoft’s Azure HDInsight, which is based on the Hortonworks platform, and Google Cloud Dataproc, which is built around the open source versions of Hadoop and Spark.
To better compete with those offerings, Cloudera — which, despite its name, still got about 90% of its revenue from on-premises deployments as of September 2019 — launched a new cloud-native platform that month. The Cloudera Data Platform technology combines elements of the separate Cloudera and Hortonworks distributions and includes support for multi-cloud environments.



{kind=link}
{kind=link}