


AWS Services List – Top 10 AWS Services
17th July 2020
AWS Code Commit
27th July 2020
Cloud Bigtable is a sparsely populated table that can scale to billions of rows and thousands of columns, enabling you to store terabytes or even petabytes of data. A single value in each row is indexed; this value is known as the row key. Cloud Bigtable is ideal for storing very large amounts of single-keyed data with very low latency. It supports high read and write throughput at low latency, and it is an ideal data source for MapReduce operations.
Cloud Bigtable is exposed to applications through multiple client libraries, including a supported extension to the Apache HBase library for Java. As a result, it integrates with the existing Apache ecosystem of open-source Big Data software.
Cloud Bigtable’s powerful back-end servers offer several key advantages over a self-managed HBase installation:
- Incredible scalability. Cloud Bigtable scales in direct proportion to the number of machines in your cluster. A self-managed HBase installation has a design bottleneck that limits the performance after a certain threshold is reached. Cloud Bigtable does not have this bottleneck, so you can scale your cluster up to handle more reads and writes.
- Simple administration. Cloud Bigtable handles upgrades and restarts transparently, and it automatically maintains high data durability. To replicate your data, simply add a second cluster to your instance, and replication starts automatically. No more managing replicas or regions; just design your table schemas, and Cloud Bigtable will handle the rest for you.
- Cluster resizing without downtime. You can increase the size of a Cloud Bigtable cluster for a few hours to handle a large load, then reduce the cluster’s size again—all without any downtime. After you change a cluster’s size, it typically takes just a few minutes under load for Cloud Bigtable to balance performance across all of the nodes in your cluster.
What it’s good for
Cloud Bigtable is ideal for applications that need very high throughput and scalability for key/value data, where each value is typically no larger than 10 MB. Cloud Bigtable also excels as a storage engine for batch MapReduce operations, stream processing/analytics, and machine-learning applications.
You can use Cloud Bigtable to store and query all of the following types of data:
- Time-series data, such as CPU and memory usage over time for multiple servers.
- Marketing data, such as purchase histories and customer preferences.
- Financial data, such as transaction histories, stock prices, and currency exchange rates.
- Internet of Things data, such as usage reports from energy meters and home appliances.
- Graph data, such as information about how users are connected to one another.
Cloud Bigtable storage model
Cloud Bigtable stores data in massively scalable tables, each of which is a sorted key/value map. The table is composed of rows, each of which typically describes a single entity, and columns, which contain individual values for each row. Each row is indexed by a single row key, and columns that are related to one another are typically grouped together into a column family. Each column is identified by a combination of the column family and a column qualifier, which is a unique name within the column family.
Each row/column intersection can contain multiple cells, or versions, at different timestamps, providing a record of how the stored data has been altered over time. Cloud Bigtable tables are sparse; if a cell does not contain any data, it does not take up any space.
For example, suppose you’re building a social network for United States presidents—let’s call it Prezzy. Each president can follow posts from other presidents. The following illustration shows a Cloud Bigtable table that tracks who each president is following on Prezzy:
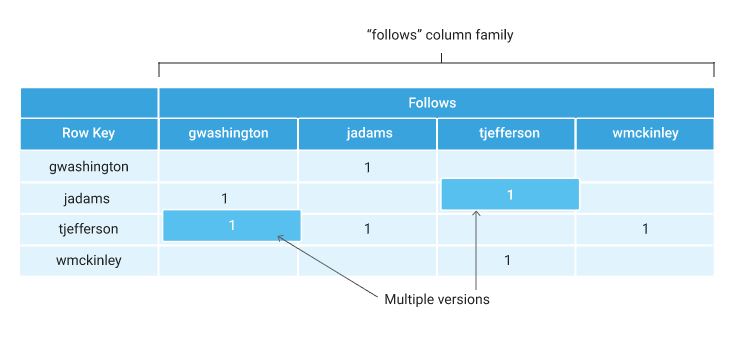
A few things to notice in this illustration:
- The table contains one column family, the
followsfamily. This family contains multiple column qualifiers. - Column qualifiers are used as data. This design choice takes advantage of the sparseness of Cloud Bigtable tables, and the fact that new column qualifiers can be added on the fly.
- The username is used as the row key. Assuming usernames are evenly spread across the alphabet, data access will be reasonably uniform across the entire table. See Load balancing to learn how Cloud Bigtable handles uneven loads and Choosing a row key for more advanced tips on picking a row key.
Cloud Bigtable architecture
The following diagram shows a simplified version of Cloud Bigtable’s overall architecture:
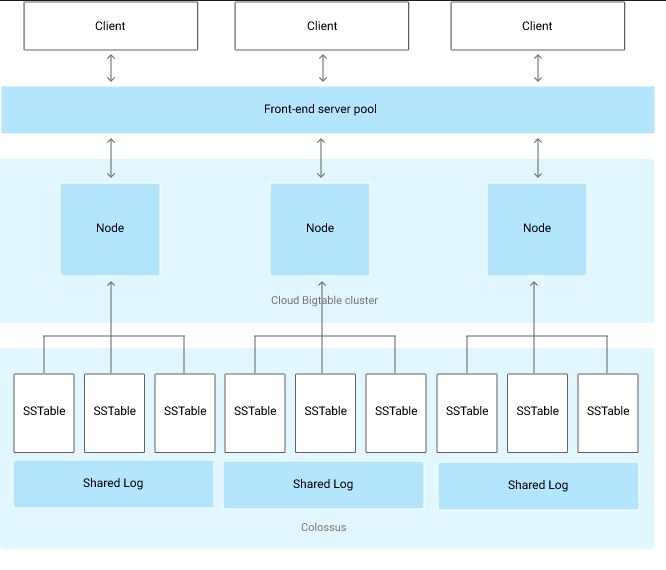
As the diagram illustrates, all client requests go through a front-end server before they are sent to a Cloud Bigtable node. (In the original Bigtable paper, these nodes are called “tablet servers.”) The nodes are organized into a Cloud Bigtable cluster, which belongs to a Cloud Bigtable instance, a container for the cluster.Note: The diagram shows an instance with a single cluster. You can also add clusters to replicate your data, which improves data availability and durability.
Each node in the cluster handles a subset of the requests to the cluster. By adding nodes to a cluster, you can increase the number of simultaneous requests that the cluster can handle, as well as the maximum throughput for the entire cluster. If you enable replication by adding a second cluster, you can also send different types of traffic to different clusters, and you can fail over to one cluster if the other cluster becomes unavailable.
A Cloud Bigtable table is sharded into blocks of contiguous rows, called tablets, to help balance the workload of queries. (Tablets are similar to HBase regions.) Tablets are stored on Colossus, Google’s file system, in SSTable format. An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Each tablet is associated with a specific Cloud Bigtable node. In addition to the SSTable files, all writes are stored in Colossus’s shared log as soon as they are acknowledged by Cloud Bigtable, providing increased durability.
Importantly, data is never stored in Cloud Bigtable nodes themselves; each node has pointers to a set of tablets that are stored on Colossus. As a result:
- Rebalancing tablets from one node to another is very fast, because the actual data is not copied. Cloud Bigtable simply updates the pointers for each node.
- Recovery from the failure of a Cloud Bigtable node is very fast, because only metadata needs to be migrated to the replacement node.
- When a Cloud Bigtable node fails, no data is lost.
See Instances, Clusters, and Nodes for more information about how to work with these fundamental building blocks.
Load balancing
Each Cloud Bigtable zone is managed by a primary process, which balances workload and data volume within clusters. This process splits busier/larger tablets in half and merges less-accessed/smaller tablets together, redistributing them between nodes as needed. If a certain tablet gets a spike of traffic, {product_name_short}} splits the tablet in two, then moves one of the new tablets to another node. Cloud Bigtable manages all of the splitting, merging, and rebalancing automatically, saving users the effort of manually administering their tablets. Understanding Cloud Bigtable Performance provides more details about this process.
To get the best write performance from Cloud Bigtable, it’s important to distribute writes as evenly as possible across nodes. One way to achieve this goal is by using row keys that do not follow a predictable order. For example, usernames tend to be distributed more or less evenly throughout the alphabet, so including a username at the start of the row key will tend to distribute writes evenly.
At the same time, it’s useful to group related rows so they are adjacent to one another, which makes it much more efficient to read several rows at the same time. For example, if you’re storing different types of weather data over time, your row key might be the location where the data was collected, followed by a timestamp (for example, WashingtonDC#201803061617). This type of row key would group all of the data from one location into a contiguous range of rows. For other locations, the row would start with a different identifier; with many locations collecting data at the same rate, writes would still be spread evenly across tablets.
See Choosing a row key for more details about choosing an appropriate row key for your data.
Supported data types
Cloud Bigtable treats all data as raw byte strings for most purposes. The only time Cloud Bigtable tries to determine the type is for increment operations, where the target must be a 64-bit integer encoded as an 8-byte big-endian value.
Memory and disk usage
The following sections describe how several components of Cloud Bigtable affect memory and disk usage for your instance.
Empty cells
Empty cells in a Cloud Bigtable table do not take up any space. Each row is essentially a collection of key/value entries, where the key is a combination of the column family, column qualifier and timestamp. If a row does not include a value for a specific key, the key/value entry is simply not present.
Column qualifiers
Column qualifiers take up space in a row, since each column qualifier used in a row is stored in that row. As a result, it is often efficient to use column qualifiers as data. In the Prezzy example shown above, the column qualifiers in the follows family are the usernames of followed users; the key/value entry for these columns is simply a placeholder value.
Compactions
Cloud Bigtable periodically rewrites your tables to remove deleted entries, and to reorganize your data so that reads and writes are more efficient. This process is known as a compaction. There are no configuration settings for compactions—Cloud Bigtable compacts your data automatically.
Mutations and deletions
Mutations, or changes, to a row take up extra storage space, because Cloud Bigtable stores mutations sequentially and compacts them only periodically. When Cloud Bigtable compacts a table, it removes values that are no longer needed. If you update the value in a cell, both the original value and the new value will be stored on disk for some amount of time until the data is compacted.
Deletions also take up extra storage space, at least in the short term, because deletions are actually a specialized type of mutation. Until the table is compacted, a deletion uses extra storage rather than freeing up space.
Backups
When possible, a table backup shares storage resources with its source table and previous backups of the table. A new backup shares almost all resources with the original table, so the backup takes up very little space. As time goes by, operations such as writes, deletes, and background table compactions cause new files to be written for the source table, while the original files are retained for the backup. This increasing divergence causes the backup to gradually take up more disk space on the cluster where it was created.
Data compression
Cloud Bigtable compresses your data automatically using an intelligent algorithm. You cannot configure compression settings for your table. However, it is useful to know how to store data so that it can be compressed efficiently:
- Random data cannot be compressed as efficiently as patterned data. Patterned data includes text, such as the page you’re reading right now.
- Compression works best if identical values are near each other, either in the same row or in adjoining rows. If you arrange your row keys so that rows with identical chunks of data are next to each other, the data can be compressed efficiently.
- Compress values larger than 1 MiB before storing them in Cloud Bigtable. This saves CPU cycles, server memory and network bandwidth. Cloud Bigtable automatically turns off compression for values larger than 1 MiB.
Data durability
When you use Cloud Bigtable, your data is stored on Colossus, Google’s internal, highly durable file system, using storage devices in Google’s data centers. You do not need to run an HDFS cluster or any other file system to use Cloud Bigtable. If your instance uses replication, Cloud Bigtable maintains one copy of your data in Colossus for each cluster in the instance. Each copy is located in a different zone or region, further improving durability.
Behind the scenes, Google uses proprietary storage methods to achieve data durability above and beyond what’s provided by standard HDFS three-way replication. In addition, we create backups of your data to protect against catastrophic events and provide for disaster recovery.
Security
Access to your Cloud Bigtable tables is controlled by your Google Cloud project and the Cloud Identity and Access Management (Cloud IAM) roles that you assign to users. For example, you can assign Cloud IAM roles that prevent individual users from reading from tables, writing to tables, or creating new instances. If someone does not have access to your project or does not have an IAM role with appropriate permissions for Cloud Bigtable, they cannot access any of your tables.
You can manage security at the project, instance, and table levels. Cloud Bigtable does not support row-level, column-level, or cell-level security restrictions.


{kind=link}
{kind=link}