
Understanding How ChatGPT Maintains Context
13th March 2024
Netflix Logo Evolution: From Initial Designs to the Iconic “Tudum!”
20th March 2024
Introduction Of ScyllaDB
ScyllaDB is one of the newest NoSQL database which offers really high throughput at sub millisecond latencies. The important point is that it accomplishes this at a fraction of the cost of a modern NoSQL database.

ScyllaDB implements almost all of the features of Cassandra in C++. But saying it’s a mere C++ port would be an understatement. Developers at Scylla have made a lot of changes under the hood which are not visible to the user but that lead to a huge performance improvemen
You are kidding, right?
No, I’m not.
As you can see (if you went to that link), for most cases, Scylla’s 99.9 percentile latency is 5–10X better than Cassandra’s.
Also in the benchmarks mentioned here, a standard 3 node Scylla cluster offers almost the same performance as a 30 node Cassandra cluster (which leads to a 10X reduction in cost).
How is this possible?
The most important point is that Scylla is written in C++14. So, it’s expected to be faster than Cassandra which purely runs on JVM.
However, there have been lots of significant low level optimizations in Scylla which makes it better than its competition.
ScyllaDB has also climbed by 200 times in DB-engines ranking in just the last few years!
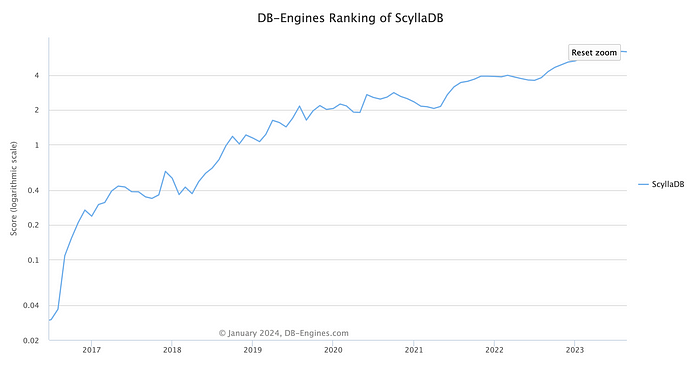
So, what is all the hype about? Why are teams moving to this newer and perhaps less production-tested database? Let’s explore what ScyllaDB is, how it works, and the reason for its fame.
Prerequisites
We need to quickly refresh over a few topics before we dive into ScyllaDB further.
JVM and Garbage Collection In ScyllaDB
Chances are you’ve heard of the JVM or Java Virtual Machine. If you haven’t, the Java Virtual Machine (JVM) is like a special translator specifically for Java programs. It takes the human-readable code you write in Java and transforms it into a language that computers can understand and execute.
This is the reason why Java became popular as a language that can run on different platforms so easily, it’s because all Java applications are abstracted by JVM. JVM provides a layer over which Java programs can run, abstracting complex problems like memory management and CPU cores.
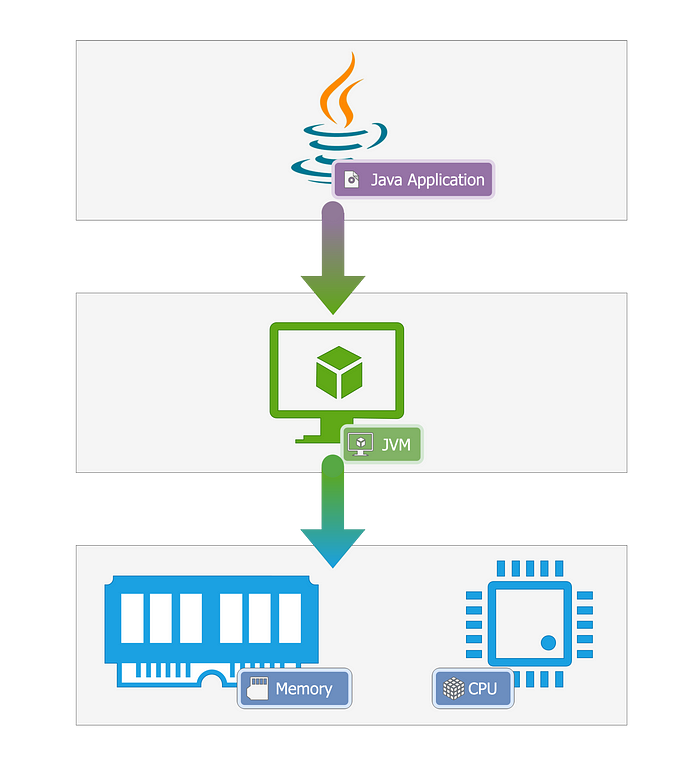
To manage memory, JVM performs an operation called “Garbage Collection”. The job of the garbage collector is straightforward, simply identify and collect all unused variables(garbage), and dispose of them. This ensures that your program is memory efficient. However, as we will soon see, this also comes with its fair share of problems.
CPU cores, Threads, Resource Contentions
Let’s quickly refresh over CPU cores, threads, and resource contention.
Most CPUs on servers are multi-core, where each core works as an independent unit and each core can run parallel to other cores. For example, assume a team of software engineers, with each engineer working on his/her feature.
For the CPU to do any work, it needs to access different resources in the system, like caches, registers, RAM, disk, network, etc. Each core, apart from its thread of execution, gets a small set of resources that it can use, like L1 and L2 caches and registers, everything else however, like disk and RAM is shared across all cores.
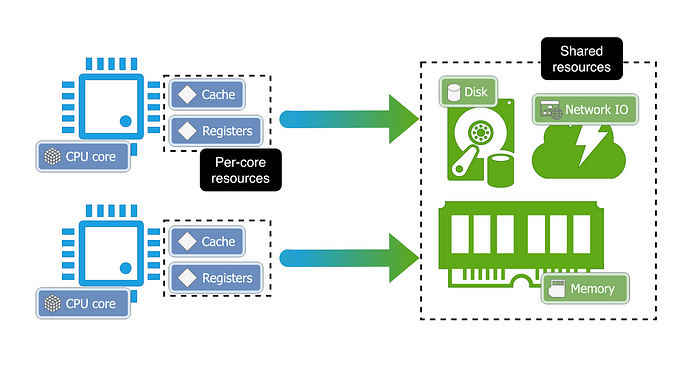
For example, in a team of software engineers, each engineer has his/her laptop, but they share access to common resources, like meeting rooms.
This shared access to common resources can get problematic though when multiple cores try to access the same resource at the same time. This often leads to cores waiting for other cores to finish using the resource. This contention can cause significant delays in executions.
Shards, And Partitions
In most distributed databases, data is divided into smaller sets, called “partitions” or “shards”.
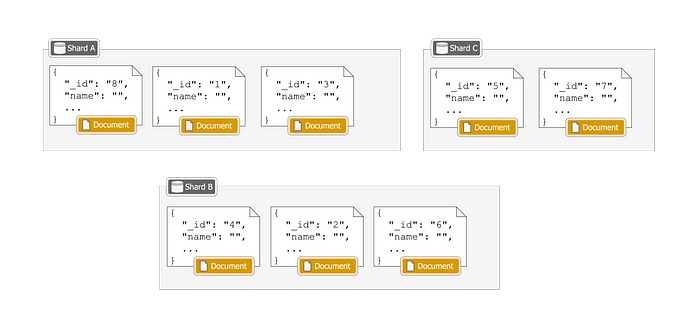
Each node stores multiple partitions, storing a subset of the entire data. This is something most databases will do internally and you don’t need to understand it in-depth to read this article but the gist of it is, that in distributed databases, data is partitioned into smaller sets (partitions or shards), with each node responsible for storing multiple partitions, thereby managing a subset of the overall dataset.
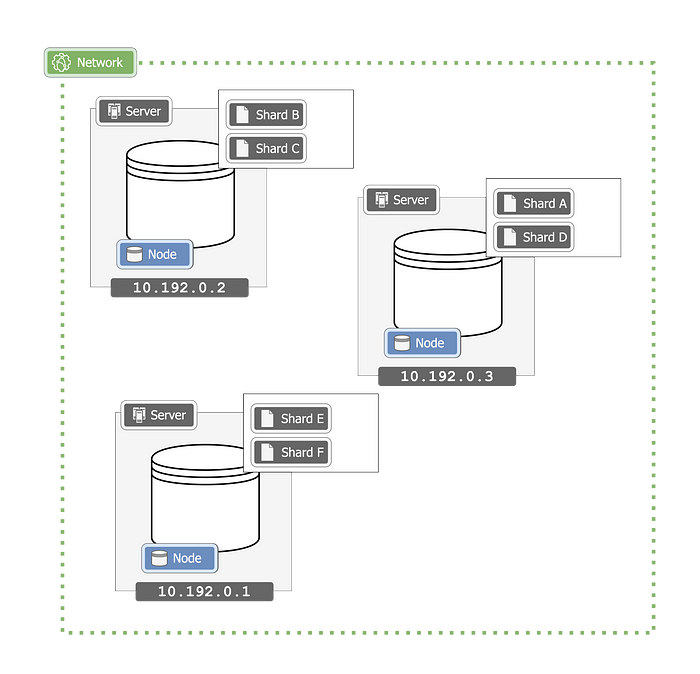
Both “Partition” and “Shard” generally mean the same, but since Cassandra uses the term “Partition” and ScyllaDB uses the term “Shard”, I’ll use them interchangeably to minimize confusion when comparing them.
Shared-Nothing Approach
Cassandra relies on threads for parallelism. The problem is that threads require a context switch, which is slow.
Also, for communication between threads, you need to take a lock on shared memory which again results in wasted processing time.
ScyllaDB uses the seastar framework to shard requests on each core. The application only has one thread per core. This way, if a session is being handled by core 1 and a query request for that session comes to core 2, it’s directed to core 1 for processing. Any of the cores can handle the response after that.
The advantage of the shared nothing approach is that each thread has its own memory, cpu, and NIC buffer queues.
In cases when communication between cores can’t be avoided, Seastar offers asynchronous lockless inter-core communication which is highly scalable. These lockless primitives include Futures and Promises, which are quite commonly used in programming and so are developer friendly.
Avoid kernel
When a row is found in an SSTable, it needs to be sent over the network to the client. This involves copying data from user space to kernel space.
However, Linux kernel usually performs multi-threaded locking operations which are not scalable.
ScyllaDB takes care of this by using Seastar’s network stack.
Seastar’s network stack runs in user space and utilises DPDK for faster packet processing. DPDK bypasses the kernel to copy the data directly to NIC buffer and processes a packet within 80 CPU cycles.
ScyllaDB Don’t rely on Page Cache
Page cache is great when you have sequential I/O and data is stored in the disk in the wire format.
However, in Scylla/Cassandra, we have data in form of SSTables. Page cache stores data in the same format, which takes up a large chunk of memory for small data and needs serialization/deserialization when you want to transfer it.
ScyllaDB, instead of relying on page cache, allocates most of its memory to row-cache.Row-Cache has the data in an optimised memory format which takes up less space and doesn’t need serialization/deserialization
Another advantage of using row cache is it’s not removed when compaction occurs while the page cache is thrashed.These are the major optimizations in ScyllaDB which make it much faster, more reliable, and cheaper than Cassandra.
For More Info: xpertlab.com



{kind=link}
{kind=link}