
8 Rules for Perfect Typography in UI
14th February 2024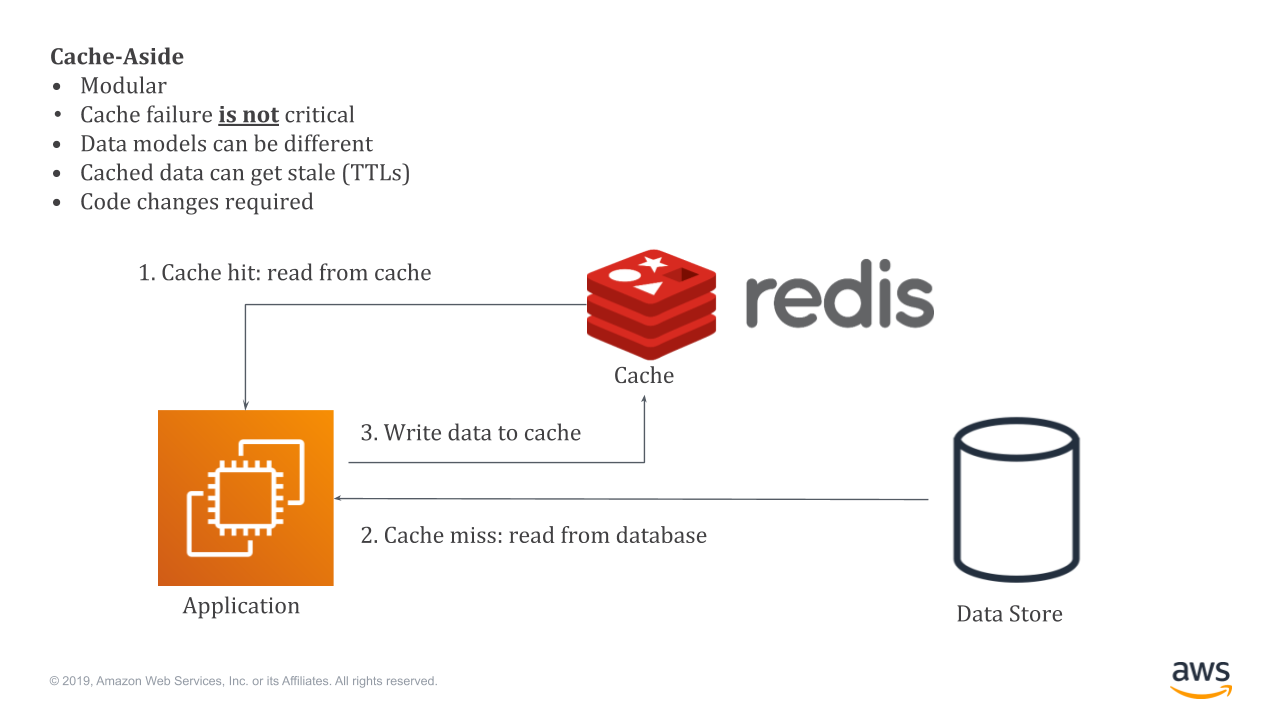
What is aws Redis?
11th March 2024
What Is Cassandra?
Cassandra is defined as an open-source NoSQL data storage system that leverages a distributed architecture to enable high availability, scalability, and reliability, managed by the Apache non-profit organization.
Working on an Apache Cassandra Project
The modern, hyperconnected world is replete with data, and there is always some new information to record and leverage. There is always new data that enterprises need to process and refer to via their applications and decision-making processes. But primarily, one must store data; this data storage for enterprise use is referred to as a database.
A database is an organized collection of stored data that can be located and accessed at will from an electronic device. Beyond storing data, some critical manipulations and operations are carried out on that data from time to time using these systems. This makes it very important to have a database and a database management system too.
A database management system or DBMS is a program that can interact with databases and other software to analyze a particular dataset. Database ecosystems include the database, management system, and associated applications. This helps us understand Cassandra better since Cassandra is all about data storage and how data is managed.
Cassandra is an open-source NoSQL distributed database that manages large amounts of data across commodity servers. It is a decentralized, scalable storage system designed to handle vast volumes of data across multiple commodity servers, providing high availability without a single point of failure.
History of Cassandra
Cassandra was created for Facebook but was open-sourced and released to become an Apache project (maintained by the Americal non-profit, Apache Software Foundation) in 2008. After that, it found top priority in 2010 and is now among the best NoSQL database systems in the world. Cassandra is trusted and used by thousands of companies because of the ease of expansion and, better still, its lack of a single point of failure. Currently, the solution has been deployed to handle databases for Netflix, Twitter, Reddit, etc.
In 2010, Cassandra was launched in its 0.6.13 version. It has since crossed twelve iterations. The latest version, 4.1.1, was launched in early 2023. Each version has come with key updates such as the addition of self-tuning memtables, Cassandra Query Language (CQL), improved compactions, compression, and read performance, among others.
How Does Cassandra Work?
Apache Cassandra, a distributed database management system, is built to manage a large amount of data over several cloud data centers. Understanding how Cassandra works means understanding three basic processes of the system. These are the architecture components it is built on, its partitioning system, and its replicability.
1. Architecture of Cassandra
The primary architecture of Cassandra is made up of a cluster of nodes. Apache Cassandra is structured as a peer-to-peer system and closely resembles DynamoDB and Google Bigtable.
Every node in Cassandra is equal and carries the same level of importance, which is fundamental to the structure of Cassandra. Each node is the exact point where specific data is stored. A group of nodes that are related to each other makes up a data center. The complete set of data centers capable of storing data for processing is what makes up a cluster.
The beautiful thing about Cassandra’s architecture is that it can easily be expanded to house more data. By adding more nodes, you can double the amount of data the system carries without overwhelming it. This dynamic scaling ability goes both ways. By reducing the number of nodes, developers can shrink the database system if necessary. Compared to previous structured query language (SQL) databases and the complexity of increasing their data-carrying capacity, Cassandra’s architecture gives it a considerable advantage.
Another way Cassandra’s architecture helps its functionality is that it increases data security and protects from data loss.
2. The partitioning system
In Cassandra, data is stored and retrieved via a partitioning system. A partitioner is what determines where the primary copy of a data set is stored. This works with nodal tokens in a direct format. Every node owns or is responsible for a set of tokens based on a partition key. The partition key is responsible for determining where data is stored.
Immediately as data enters a cluster, a hash function is added to the partition key. The coordinator node (the node a client connects to with a request) is responsible for sending the data to the node with the same token under that partition.
3. Cassandra’s replicability
Another way Cassandra works is by replicating data across nodes. These secondary nodes are called replica nodes, and the number of replica nodes for a given data set is based on the replication factor (RF). A replication factor of 3 means three nodes cover the same token range, storing the same data. Multiple replicas are key to the reliability of Cassandra.
Even when one node stops functioning, temporarily or permanently, other nodes hold the same data, meaning that data is hardly ever wholly lost. Better still, if a temporarily disrupted node is back on track, it receives an update on the data actions it may have missed and then catches up to speed to continue functioning.
Key Features of Cassandra
Cassandra is a unique database system, and some of its key features include:

1. Open-source availability
Nothing is more exciting than getting a handy product for free. This is probably one of the significant factors behind Cassandra’s far-reaching popularity and acceptance. Cassandra is among the open-source products hosted by Apache and is free for anyone who wants to utilize it.
2. Distributed footprint
Another feature of Cassandra is that it is well distributed and meant to run over multiple nodes as opposed to a central system. All the nodes are equal in significance, and without a master node, no bottleneck slows the process down. This is very important because the companies that utilize Cassandra need to constantly run on accurate data and can not tolerate data loss. The equal and wide distribution of Cassandra data across nodes means that losing one node does not significantly affect the system’s general performance.
3. Scalability
Cassandra has elastic scalability. This means that it can be scaled up or down without much difficulty or resistance. Cassandra’s scalability once again is due to the nodal architecture. It is intended to grow horizontally as your needs as a developer or company grow. Scaling-up in Cassandra is very easy and not limited to location. Adding or removing extra nodes can adjust your database system to suit your dynamic needs.
Another exciting point about scaling in Cassandra is that there is no slow down, pause or hitch in the system during the process. This means end-users would not feel the effect of whatever happened, ensuring smooth service to all individuals connected to the network.
4. Cassandra Query Language
Cassandra is not a relational database and does not use the standard query language or SQL. It uses the Cassandra query language (CQL). This would have posed a problem for admins as they would have to master a whole new language – but the good thing about Cassandra Query language is that it is very similar to SQL. It is structured to operate with rows and columns, i.e., table-based data.
However, it does lack the flexibility that comes with the fixed schema of SQL. CQL combines the tabular database management system and the key value. It operates using the data type operations, definition operation, data definition operation, triggers operation, security operations, arithmetic operations, etc.
5. Fault tolerance
Cassandra is fault-tolerant primarily because of its data replicative ability. Data replication denotes the ability of the system to store the same information at multiple locations or nodes. This makes it highly available and tolerant of faults in the system. Failure of a single node or data center does not bring the system to a halt as data has been replicated and stored across other nodes in the cluster. Data replication leads to a high level of backup and recovery.
6. Schema free
SQL is a fixed schema database language making it rigid and fixed. However, Cassandra is a schema-optional data model and allows the operator to create as many rows and columns as is deemed necessary.
7. Tunable consistency
Cassandra has two types of consistency – the eventual consistency and the setting consistency. The string consistency is a type that broadcasts any update or information to every node where the concerned data is located. In eventual consistency, the client has to approve immediately after a cluster receives a write.
Cassandra’s tunable consistency is a feature that allows the developer to decide to use any of the two types depending on the function being carried out. The developer can use either or both kinds of consistency at any time.
8. Fast writes
Cassandra is known to have a very high throughput, not hindered by its size. Its ability to write quickly is a function of its data handling process. The initial step taken is to write to the commit log. This is for durability to preserve data in case of damage or node downtime. Writing to the commit log is a speedy and efficient process using this tool.
The next step is to write to the “Memtable” or memory. After writing to Memtable, a node acknowledges the successful writing of data. The Memtable is found in the database memory, and writing to in-memory is much faster than writing to a disk. All of these account for the speed Cassandra writes.
9. Peer-to-peer architecture
Cassandra is built on a peer-to-peer architectural model where all nodes are equal. This is unlike some database models with a “slave to master” relationship. That is where one unit directs the functioning of the other units, and the other unit only communicates with the central unit or master. In Cassandra, different units can communicate with each other as peers in a process called gossiping. This peer-to-peer communication eliminates a single point of failure and is a prominent defining feature of Cassandra.
Limitations of Cassandra
Despite all of these benefits, Cassandra has its share of limitations:
- Firstly, there is no official documentation from Apache, which makes it necessary to take the risk of sourcing the tool from third-party platforms.
- Cassandra does not provide support for relational and ACID database properties.
- While Cassandra provides superior performance in write operations, read operations are sub-optimal.
- Latency issues are a common problem when managing large amounts of data and requests.
- Cassandra also does not provide support for aggregates and subqueries.
- Cassandra stores the same data multiple times as it is based on queries, which in turn results in Java Memory Model (JVM) issues.
Top 6 Uses of Cassandra
Cassandra is an open-source NoSQL database management system with many advantages and practical functionalities that rival other systems. It is used by several large and small companies across the globe. Some of the top applications of Cassandra include:
1. E-commerce
E-commerce is an extremely sensitive field that cuts across every region and country. The nature of financial markets means anticipated peak times as well as downtimes. For a finance operation, no customer would want to experience downtime or lack of access when there is revenue to be earned and lots of opportunities to hold on to. E-commerce companies can avoid these downtimes or potential blackouts by using a highly reliable system like Cassandra. Its fault tolerance allows it to keep running even if a whole center is damaged with little or no hitch in the system.
Due to its easy scalability, especially in peak seasons, E-commerce and inventory management is also a significant application of Cassandra. When there is a market rush, the company has to increase the ability of the database to carry and store more data. The seasonal, rapid E-commerce growth that is affordable and does not cause system restart is simply a perfect fit for companies.
E-commerce websites also benefit from Cassandra as it stores and records visitors’ activities. It then allows analytical tools to modulate the visitor’s action and, for instance, tempts them to stay on the website.
2. Entertainment websites
With the aid of Cassandra, websites for movies, games and music can keep track of customer behavior and preferences. The database records for each visitor, including what was clicked, downloaded, time spent, etc. This information is analyzed and used to recommend further entertainment options to the end-user.
This application of Cassandra falls under the personalization, recommendation and customer experience use cases. It is not just limited to entertainment sites, but also online shopping platforms and social media recommendations. This is why users would receive notifications of similar goods to what they spent time browsing.
3. Internet of Things (IoT) and edge computing
Today’s world is seeing the rise of the Internet of Things (IoT). We are steadily bombarded with thousands of new information points or datasets. Every wearable device, weather sensor, traffic sensor, or mobile device keeps track of and sends data on weather, traffic, energy usage, soil conditions, etc. This flood of information can be overwhelming and easily lost.
However, storing and analyzing information from IoT devices, no matter how large, has become much more effective on Cassandra technology. This is due to (but not limited to) the following reasons:
- Cassandra allows every individual node to carry out read and write operations.
- It can handle and store a large amount of data.
- Cassandra supports the analysis of data in real-time.
4. Authentication and fraud detection
Fraud detection is essential to the security and reliability of many companies, mainly banks, insurance and other financial institutions. At all points, these companies must ensure that they can beat the new, revamped way of stealing data developed by fraudsters. Financial companies aim to keep fraudsters and hackers away from their systems. Cassandra is applicable here due to continuous, real-time, big data analytics. Casandra can source data across a wide range of internet activities that can trigger alarms when patterns and irregularities that may be preceded by fraud are detected.
On the other hand, these same financial institutions are required to carry out a seamless identity authentication process. To make the user login authentication process tight enough to allow only genuine customers yet simple enough to make it easy for them, Cassandra helps to carry out a real-time analysis. In addition to these analyses, Cassandra is also vital because, with it, you can be sure of constant accessibility.
In general, Cassandra is among the top database options chosen to detect fraud and carry out authentication processes because:
- It allows for real-time analysis with machine learning and artificial intelligence (AI).
- It can host large amounts of actively growing data sets.
- It has a flexible schema to allow the processing of different data types.
5. Messaging
There are currently several messaging applications in use, and an ever-growing number of individuals are using them. This creates the need for a stable database system to store ever-flowing information volumes. Cassandra provides both stability and storage capacity for companies that offer messaging services.
6. Logistics and asset management
Cassandra is used in logistics and asset management to track the movement of any item to get transported. From the purchase to the final delivery, applications can rely on Cassandra to log each transaction. This is especially applicable to large logistic companies regularly processing vast amounts of data. Cassandra had found a robust use case in backend development for such applications. It stores and analyzes data flowing through without impacting application performance.



{kind=link}
{kind=link}
{kind=link}