


Next Level Visuals with Adobe Photoshop
10th February 2020
Reason for Slow Website Loading
11th February 2020
Android Development Company Junagadh
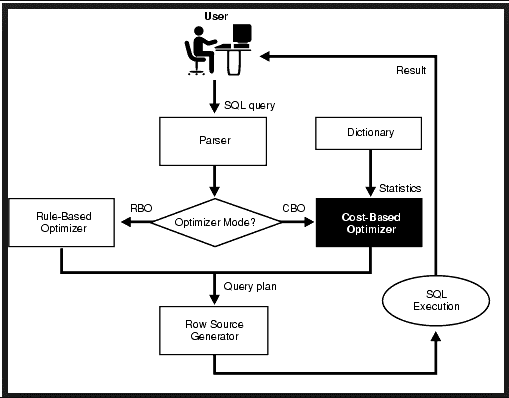
SQL optimization techniques have always been a popular topic in database management. SQL database optimization techniques can be an extremely difficult task, in particular for large-scale data wherever a minute variation can result or impact drastically on the performance. Although SQL programming looks easy to learn and the commands used don’t point to an algorithm that retrieves data, its straightforwardness, however, takes it in a deceptive manner.
In this SQL optimization techniques article, I will be sharing some of the best SQL optimization techniques with my readers. They are as follows:
- The Execution plan over SQL Server DBA could be used in writing indexes. The main function of it is to graphically display data by retrieving from the SQL Server query optimizer.
- To get back the execution plan (in SQL Server Management Studio), click on ‘Include Actual Execution Plan (Ctrl+M)’ prior to running the SQL query.
- Thereon, a 3rd tab called ‘Execution Plan’ will pop up with detected missing index. Right click on the execution plan and There’s a ‘missing index details’ choosing that will resolve the issue.
Android Development Company Junagadh
Use CASE instead of UPDATE
- Although using UPDATE is a natural form which seems logical, many developers overlook it and also it is easy to spot.
- For example, when inserting data into a temp table and if you want to display a value where it already exists. For example, if any of the customers with more ratings needs to be “preferred”, then when it runs, it inserts data into the table and runs an UPDATE and then the column is set to prefer. The drawback is that each time the UPDATE statement is done, it has to run two times, for every single write to the table.
- To solve this usage of inline CASE in SQL query resolves by testing every row for the rating and state is set to ‘Preferred’.
- Hence, performance is not hindered.
How to Optimize “Query” Checklist
- Lots of problems occur when we put a lot of tables in SQL in a single join operation. The near fix is to do half the join with less number of tables and cache the output in a temporary table. Then carry on with the rest of the query on the temporary table.
- Run UPDATE STATISTICS on below SQL tables
- Many systems will run this for optimizing the weekly data on a scheduled basis.
- Archive the deleted records or delete it from the below SQL tables
- Doing this in scheduled mode once a week or a day will optimize Checklist.
- Rebuild Indexes, tables
- Dumping the SQL database(instant but will help fix corruption)
- Running DBCC will also check possible corruption in the database
Limit the size of the Working Data Set
- Verify the tables used in the SELECT to check if any possible filters can be applied to WHERE statement. As during the span of time, the SQL query grows, the solution would be to look or specify the query to check only the limited or monthly data.
Removing Outer Joins
- This depends on the capacity or influence a person has for changing the table content.
- The possible solution is to remove OUTER JOINS by keeping placeholder rows in both tables. Example, the below table with OUTER JOIN defined to guarantee all info is getting.
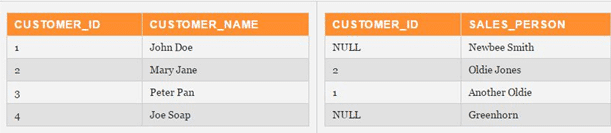
Resolving this is to add a placeholder row into the table of customers and UPDATE all NULL values to the placeholder key in the sales table

- Not only it removed the urge of OUTER JOIN but also made it a standard for salespeople with no customers.
- This eliminates the need for developers to write the following statement ISNULL(customer_id, “Customers is zero”).
When to use temp tables
- This problem is yet another quite difficult to go through. We can use a temp table in no. of areas, for as stopping from double-dipping to the big tables. This can also be used to drastically reduce the processing power mandatory to join big amounts of data.
- When joining of data from one table to a large table, the performance hindering is reduced when the subset of big table data is joined after pulling out of it. This will also work when we have several queries to make similar joins at the same table.

{kind=link}
{kind=link}