
NoSQL Database
30th January 2020
Risk Management in Testing
5th February 2020
Today, Hadoop has the privilege of being one of the most widespread technologies when it comes to crunching huge amounts of Big Data. Hadoop is like an ocean with a vast array of tools and technologies that are exclusively associated with it. One such technology is Apache Hive. Apache Hive is a Hadoop component that is normally deployed by data analysts. Even though Apache Pig can also be deployed for the same purpose, Hive is used more by researchers and programmers. It is an open-source data warehousing system, which is exclusively used to query and analyze huge datasets stored in Hadoop.
The three important functionalities for which Hive is deployed are data summarization, data analysis, and data query. The query language, exclusively supported by Hive, is HiveQL. This language translates SQL-like queries into MapReduce jobs for deploying them on Hadoop. HiveQL also supports MapReduce scripts that can be plugged into the queries. Hive increases schema design flexibility and also data serialization and deserialization.
Most important file systems supported by Hive are:
- Flat files or text files
- Sequence files consisting of binary key–value pairs
- RCFiles that store columns of a table in a columnar database
Architecture of Apache Hive
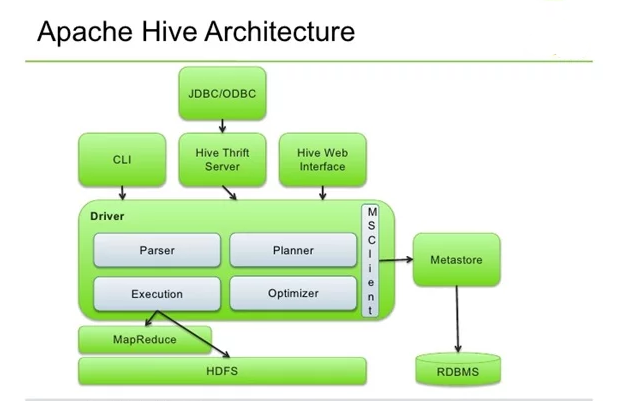
Major Components of Hive Architecture
Metastore: It is the repository of metadata. This metadata consists of data for each table like its location and schema. It also holds the information for partition metadata which lets you monitor various distributed data progresses in the cluster. This data is generally present in the relational databases. The metadata keeps track of the data, replicates it, and provides a backup in the case of data loss.
Driver: The driver receives HiveQL statements and works like a controller. It monitors the progress and life cycle of various executions by creating sessions. The driver stores the metadata that is generated while executing the HiveQL statement. When the reducing operation is completed by the MapReduce job, the driver collects the data points and query results.
Compiler: The compiler is assigned with the task of converting a HiveQL query into a MapReduce input. It includes a method to execute the steps and tasks needed to let the HiveQL output as needed by MapReduce.
ptimizer: This performs various transformation steps for aggregation and pipeline conversion by a single join for multiple joins. It also is assigned to split a task while transforming data, before the reduce operations, for improved efficiency and scalability.
Executor: The executor executes tasks after the compilation and optimization steps. It directly interacts with the Hadoop Job Tracker for scheduling the tasks to be run.
CLI, UI, and Thrift Server: The command-line interface (CLI) and the user interface (UI) submit queries and process monitoring and instructions so that the external users can interact with Hive. Thrift Server lets other clients interact with Hive.
Why use Apache Hive?
Apache Hive is mainly used for data querying, analysis, and summarization. It helps improve developers’ productivity which usually comes at the cost of increasing latency. Hive is a variant of SQL and a very good one indeed. It stands tall when compared to SQL systems implemented in databases. Hive has many user-defined functions that offer effective ways of solving problems. It is easily possible to connect Hive queries to various Hadoop packages like RHive, RHipe, and even Apache Mahout. Also, it greatly helps the developer community work with complex analytical processing and challenging data formats.
Data warehouse refers to a system used for reporting and data analysis. What this means is inspecting, cleaning, transforming, and modeling data with the goal of discovering useful information and suggesting conclusions. Data analysis has multiple aspects and approaches, encompassing diverse techniques under a variety of names in different domains.
Hive allows users to simultaneously access data and, at the same time, increases the response time, i.e., the time a system or a functional unit takes to react to a given input. In fact, Hive typically has a much faster response time than most other types of queries. Hive is also highly flexible as more commodities can easily be added in response to adding more clusters of data without any drop in performance.
What are the advantages of learning Hive?
Apache Hive lets you work with Hadoop in a very efficient manner. It is a complete data warehouse infrastructure that is built on top of the Hadoop framework. Hive is uniquely deployed to come up with querying of data, powerful data analysis, and data summarization while working with large volumes of data. The integral part of Hive is HiveQL which is an SQL-like interface that is used extensively to query data that is stored in databases.
Hive has a distinct advantage of deploying high-speed data reads and writes within data warehouses while managing large datasets distributed across multiple locations, all thanks to its SQL-like features. Hive provides a structure to the data that is already stored in the database. Users are able to connect with Hive using a command-line tool and a JDBC driver.