
What’s the difference between JavaScript and JScript?
11th August 2021
7 Java Web Development Technologies You Must Know In 2021–22
20th August 2021
DynamoDB is a key-value, NoSQL database developed by Amazon. It’s unlike some other products offered by Amazon and other vendors in that it’s not just an open-source system, like Spark, hosted on the vendor’s platform.
How does DynamoDB work?
DynamoDB looks just like JSON, with the one difference being that each JSON record must include the record key. That has the advantage that it lets you do updates on a record. In a JSON database, like MongoDB, you cannot update records. Instead, you must delete them then add back the changed version to affect the same change.
DynamoDB also lets you work with transactions, something that MongoDB supports as well. Not all NoSQL databases let you do that. This is important as certain database operations logically must go together. For example, a sales transaction must both decrement inventory and increase cash on hand. If one of those two operations failed then the sales and inventory systems would be out of balance.
You work with the database using the AWS command-line client, APIs for different programming languages, their NoSQL workbench desktop tool, or on the Amazon AWS website.
DynamoDB Definitions
DynamoDB has these concepts and more:
- Table: a collection of items
- Item: a collection of attributes. (Other databases call these records or documents.)
- Stream: like a cache that holds changes in memory until they are flushed to storage.
- Partition key: the primary key. It must be unique.
- Partition key and sort key: a composite primary key, meaning a partition key with more than one attribute, like employee name and employee ID (necessary because two employees could have the same name).
- Secondary indexes: you can index other attributes that you frequently query to speed up reads.
API and SDK
As with most cloud systems, DynamoDB exposes its services via web services. But that does not mean you have to format your data to JSON and then post it using HTTP. Instead, they provide software development kits (SDKs). The SDK takes the requests you send it and then translates that to HTTP calls behind the scenes. In this way, the SDK provides a more natural and far less wordy way to work with the database. The SDK lets you work with DynamoDB as you would work with regular objects.
The SDK has these methods:
- PutItem
- BatchWriteItem
- GetItem
- BatchGetItem
- Query
- Scan
- UpdateItem
- DeleteItem
- ListStreams
- GetShardIterator
- GetRecords
- TransactWriteItems
- TransactGetItems
AWS CLI
As with other Amazon products you can use the AWS command-line client. That lets you run database operations from the command line without having to write a program. You use JSON to work with DynamoDB.
For example, there are these operations and a few more:
- AWS DynamoDB create-table
- aws dynamodb put-item
SDKs
DynamoDB has SDKs for these programming languages:
- Java
- JavaScript
- .NET
- js
- PHP
- Python
- Ruby
- C++
- Go,
- Android
- iOS
For Java and .NET, they provide objects. Those let you work with table items as if they were objects in those programming languages. And it translates from data types, letting you use, for example, you can use dates and bytes instead of being limited to facsimiles of those as strings or numbers, as you would with JSON.
Amazon DynamoDB Accelerator (DAX)
DAX is an optional feature that turns DynamoDB into an in-memory database.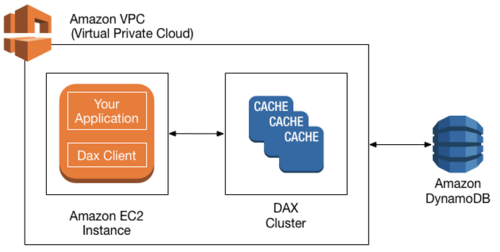
Integration with other systems
- Amazon Glue. In this case, you pull data from DynamoDB into Amazon Glue. There you to ETL and then write it out to other systems like the Amazon Redshift data warehouse.
- Apache Hive on Amazon EMR. This is more a back-and-forth interface. You can use this to, for example, using HiveQL (the Hive SQL language) to query DynamoDB tables. And you can copy data into Hadoop. (Hive rides atop Hadoop to support EMR, which is the MapReduce operation.) You can also join DynamoDB tables in Hive.



{kind=link}
{kind=link}
{kind=link}