


What is Git Desktop
19th October 2021
Redis
28th October 2021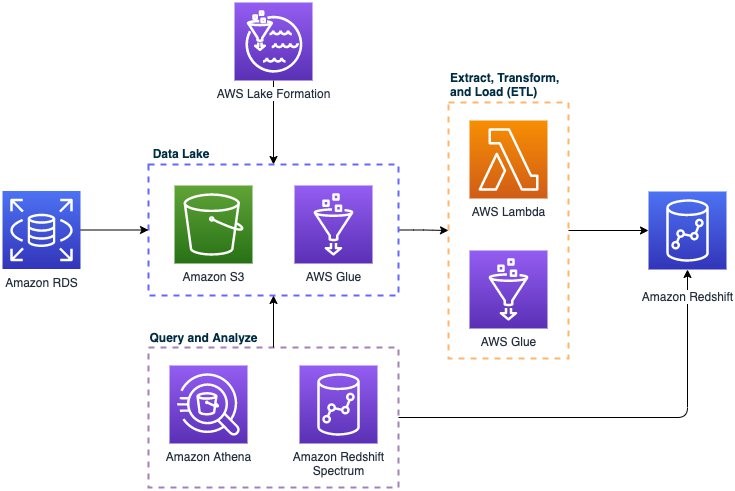
As the volume of customers’ data grows, companies are realizing the benefits that data has for their business. Amazon Web Services (AWS) offers many database and analytics services, which give companies the ability to build complex data management workloads. At the same time, these services can reduce the operational overhead compared to traditional operations.
Using core managed AWS analytics services will enable you to spend more time focusing on how to use your data, and less time managing and maintaining the underlying infrastructure. Let’s review the core data and analytics services you can use to support these needs.
Scale and Update Your Transactional Workloads
Many companies have workloads that require thousands of writes to a database. These workloads often result in large numbers of inserts, updates, and deletes, which can be input/output intensive. As these workloads increase, self-managed databases require maintenance, backups, patching, and hardware provisioning to keep up with this demand. Amazon Relational Database Service (RDS) allows you to set up and quickly scale familiar database engines such as MySQL, PostgreSQL, and Microsoft SQL Server. At the same time, it alleviates database administrators from time-consuming operations.

Moving Data from Transactional Databases to Data Lakes
Amazon RDS supports online transactional processing databases (OLTP), which efficiently handle create, read, update, and delete (CRUD) operations. Moving your data from a transactional database to a data lake will reduce storage stress on the transactional database and optimize computation-heavy analytics queries. This also will provide you with a centralized repository capable of combining mixed data structures from different data sources for analytics and storage. AWS Lake Formation makes it possible to set up a data lake in a matter of days, and is built on Amazon Simple Storage Service (Amazon S3). AWS Lake Formation allows customers to integrate their centralized storage with most database engines supported by RDS through AWS Lake Formation’s blueprints feature. By using AWS Lake Formation to create a data lake, customers have the flexibility to hydrate their data lake with a full copy of the database through a database snapshot, or through incremental data loads.

Extracting, Transforming, and Loading Data
Storing data in a data lake provides the flexibility to store mixed data structures from disparate sources. This data may require additional processing such as standardization and normalization, for use in AWS storage and analytics services.
The ability for customers to catalog and process their data ensures accuracy, reliability, and consistency of this data across multiple data stores.
Customers can take advantage of AWS Glue to catalog, process, and combine their data. AWS Glue is a serverless data integration service, and provides visual and code-based interfaces for data integration. Customers can automatically detect and discover metadata and data schemas across different data sources, by using the AWS Glue Crawler feature. You can use the AWS Glue Jobs feature to automate your Extract, Transform, and Load (ETL) workloads. Use AWS Glue, when your goal is to catalog and organize many data stores, or to use the Apache Spark framework for your ETL workloads.

Customers can also use AWS Lambda to write and develop custom ETL scripts in languages, such as Node.js and Python, while maintaining control of the underlying runtime environment. AWS Lambda is a serverless compute service that allows users to run code without provisioning servers. Lambda can run code for almost any workload and allows for importing of custom packages. If you run your ETL workloads with common Python modules such as Pandas and numPy, you can package and include these modules in your AWS Lambda environment. Use AWS Lambda when you have smaller workloads and require more flexibility in building out your code and have custom package dependencies.

Data Warehouse Services
Customers rely on reports, dashboards, and analytics tools to extract insights from their data, monitor business performance, and support decision making. Customers can use a data warehouse to improve the performance of computation-heavy analytics requirements across petabytes of data. Amazon Redshift is a fully managed data warehouse that provides exceptional performance for analytics queries. Amazon Redshift reduces the operational overhead required with traditional data warehouses by automating tasks such as patching, backups, and hardware provisioning. You can configure an Amazon Redshift cluster where you can customize the infrastructure and performance baselines for your data warehouse. Amazon Redshift also provides Redshift Spectrum, which allows you to use Amazon Redshift cluster resources to query and join data with Amazon S3.
Running Queries on Data in Data Lakes
When storing data on Amazon S3, customers benefit from cost efficiency and durability. You can use standard SQL to query data within Amazon S3 without having to preprocess or index the data for analysis. This allows customers to reap the cost savings that Amazon S3 provides, in addition to deriving insights without moving the data.
You can run queries using Amazon Athena, which is a serverless query service that uses standard SQL to query data in Amazon S3. There is no infrastructure to manage with Amazon Athena. You can take advantage of high-performance queries while realizing storage cost savings associated with the data lake built on Amazon S3. Because Amazon Athena is serverless, you only pay for the resources consumed. You are charged based on the amount of data that is scanned with each query.
In the situation where you have provisioned an Amazon Redshift data warehouse, Amazon Redshift Spectrum is an additional service that queries data in Amazon S3. Redshift Spectrum is associated with an Amazon Redshift cluster and provides more control over performance. If you want to increase query performance, you can allocate additional compute resources. The cost of Redshift Spectrum is similar to that of Athena, in which you are charged for the amount of data that is scanned.
Putting it all Together
Using the concepts discussed in this blog post, customers can implement the following architecture to build the foundation of a data platform. This platform will reduce your operational load by using managed services in AWS:



{kind=link}
{kind=link}